You've spent years building institutional knowledge — policies, procedures, contracts, research, training materials. Episteca turns that into a series of AI experts that work entirely from what you've given them.
Knowledge locked in documents nobody reads.
You have knowledge locked in documents nobody reads, held by people who will eventually leave, distributed through training nobody trusts.
Episteca solves this. We turn your institutional knowledge into deep domain AI experts that are bounded to what you've given them — and nothing else.
Everything cited.
No faking.
They write for you. They retrieve for you. They create complete courses for you.
When you ask them something, they go into your documents and bring back the answer with the source attached. When something isn't there, they say so. That's not a weakness. That's the point.
Everything they produce is cited directly from your documents. No faking.
The Episteca Difference
No Faking
Everything they produce is cited directly from your documents. You get real answers with the source attached.
Bounded Experts
When something isn't there, they say so. That's not a weakness. That's the point.
Continuous Growth
They build on from your knowledge base. Upload something new and they expand. Update a document and they reflect it. The more you give them, the more they can do.
Total Privacy
And your data never leaves your building. No data is stored in our systems. Nothing is used to train our models or anyone else's. The experts live inside your environment, entirely under your control.
Bounded to your knowledge base.
An Episteca expert knows only what you give it. Every piece of content it generates is cited directly from your source documents.
No hallucination, no invented information, no confident answers drawn from the internet. If the answer is not in your documents, the expert says I don't know. That honesty is not a limitation. It is the product.
From your uploaded documents the expert can write training modules, generate assessments, produce complete courses, create AI-narrated video and audio, answer questions across your entire knowledge corpus, retrieve specific obligations from contracts, evaluate suppliers against your own criteria, and write proposals grounded in your previous work.
Generate from Documents
Write training modules, generate assessments, produce complete courses, create AI-narrated video and audio from your uploaded corpus.
Traceable Claims
Every output is cited. Every claim is traceable. Every gap in the knowledge base is surfaced before it becomes a problem.

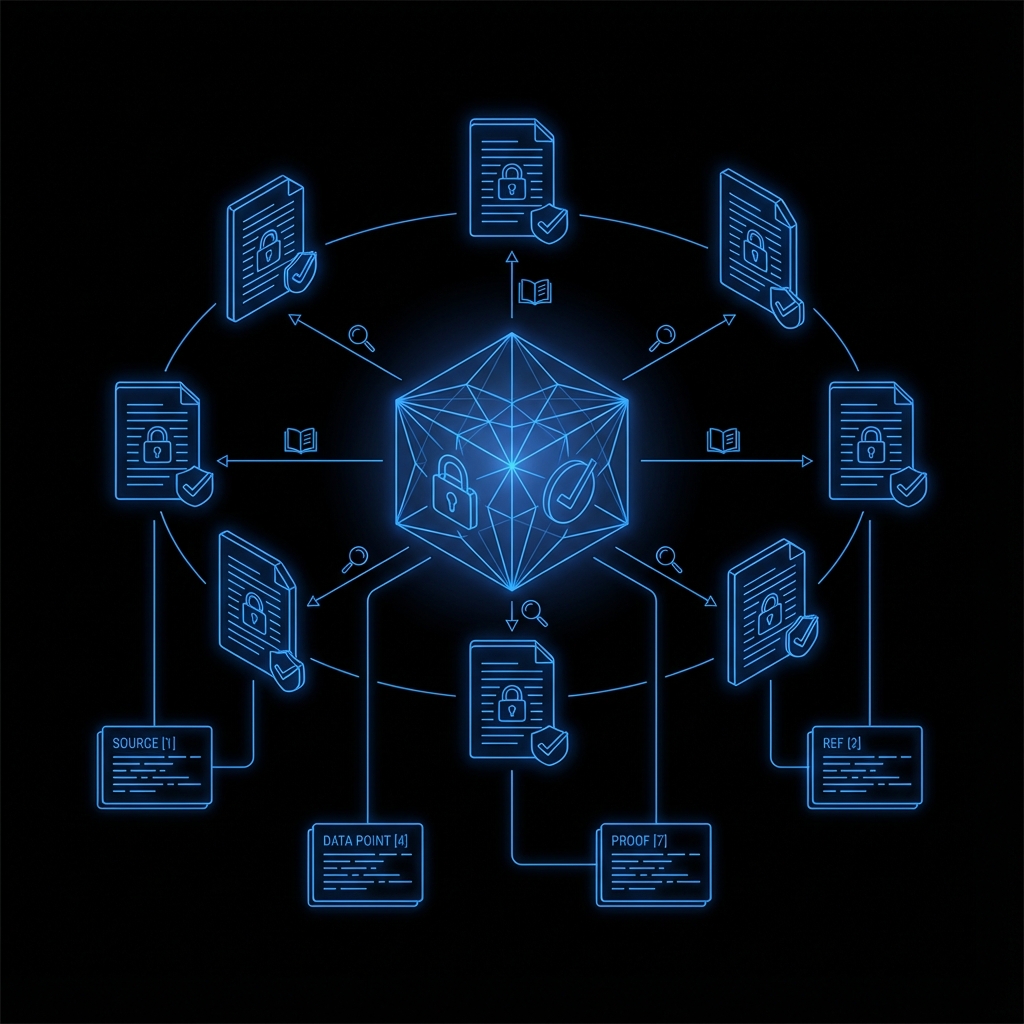
The Semantic Map
You upload your documents. Every sentence gets a mathematical fingerprint based on its meaning — not just its words, but the relationships between ideas. Similar concepts cluster together. What emerges is a complete semantic map of everything your organization knows, built from what your organization actually wrote.
The expert can only speak from that map.
01. Bounded Search Paths
When someone asks a question, three search paths run at the same time: meaning, exact terms, and relationships. The results are fused and reranked.
02. Pre-Generation Check
Before the expert writes a single word, it checks that it actually has enough to say something true. If it doesn't, it stops.
03. Verification Layer
After generation, a verification layer reads each source against each claim. Anything that doesn't pass is cut before it reaches you.
04. It Grows With You
Upload a new document and it expands. Update a policy and the training reflects it. The knowledge base is never finished.
Your data never leaves your building.
Episteca deploys inside your own environment. No data is stored on Episteca's servers. Nothing is used to train external models.
No external cloud
After installation, Episteca has zero access to your environment. No telemetry. No usage data. No connection back to our systems. The software runs independently once installed. We cannot see what your expert knows, what your team asks it, or what it answers.
No API calls
The AI models run locally on your hardware. There are no calls to OpenAI, Anthropic, Google, or any external model provider. The models are bundled inside the software.
No internet required
In environments with no internet connectivity at all, the full platform operates without modification. Air-gapped facilities, closed networks, restricted infrastructure.
You control access
You decide who can access which expert, which documents, and which outputs. Those boundaries are enforced automatically. Different teams see different knowledge bases. Sensitive documentation reaches only those with the right clearance.
We started with one question.
How do you build AI that knows what it doesn't know?
Most organizations have the same problem. The knowledge is there — in the documents, built up over years by people who understood the domain deeply. The problem is making it accessible, accurately, to the people who need it every day, in a way they can actually trust.
General AI doesn't solve this. It answers from the internet, not from your procedures. It sounds confident when it's wrong. And it has no way to tell you when it's making something up.
We built something different. Experts that are bounded to your knowledge. Everything cited. Nothing invented. Deployed inside your own environment where your data stays yours.
Episteca was founded in Cambridge, Massachusetts in 2025, at the intersection of MIT Media Lab and Harvard Design Engineering. The name comes from the Greek root for knowledge — the same root as epistemology. The study of what it means to know something, and when you actually don't. That question is the foundation of everything we've built.